
Why We Use Both Python and C++ in Computer Vision Projects
Modern computer vision projects are not only about training accurate AI models. To build a system that performs well in real-world deployments, it is equally important to consider runtime speed, real-time responsiveness, memory efficiency, software architecture, and long-term maintainability.
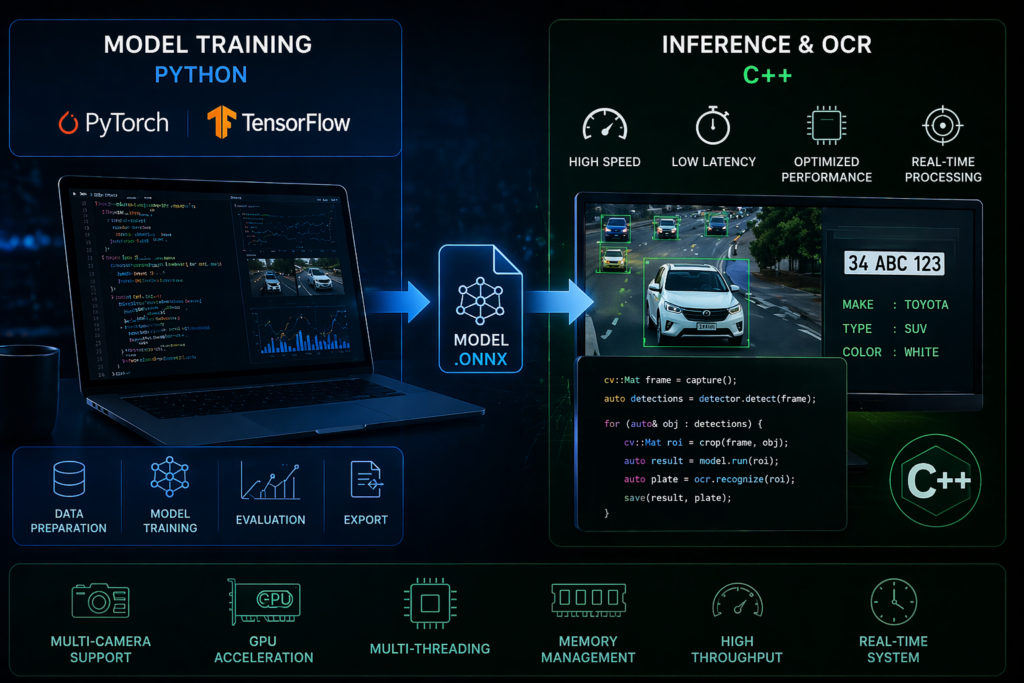
In projects such as OCR, license plate recognition, vehicle make / type / color recognition, container code recognition, and wagon code recognition, the training environment and the runtime environment often require different technology choices.
In our approach, model training is performed in Python, while OCR processing, inference, and runtime operations are implemented in C++. This architecture provides strong advantages in both development flexibility and field performance.

Why Model Training Is Done in Python
Python has become the standard language for AI research, model development, and deep learning training workflows. There are several reasons for this:
- broad framework support
- fast experimentation
- efficient data preparation pipelines
- strong community and research ecosystem
- quick adaptation to new model architectures
For this reason, we use powerful frameworks such as PyTorch and TensorFlow on the training side. These frameworks make it easier to build, train, evaluate, fine-tune, and export modern deep learning models.
Python is especially efficient for tasks such as:
- dataset preparation
- annotation conversion and preprocessing
- training pipeline development
- experimental model design
- hyperparameter optimization
- performance evaluation
- model export to deployment-ready formats such as ONNX
In short, Python offers excellent flexibility for the research and development phase of computer vision systems.
We Use Modern Deep Learning Techniques and Models
Today’s successful computer vision systems go far beyond traditional image processing methods. To solve real-world visual recognition problems effectively, it is necessary to use modern deep learning techniques and state-of-the-art model architectures.
In our training workflows, we use technologies and approaches such as:
- deep neural networks
- modern CNN-based architectures
- object detection models
- OCR pipelines based on detection + recognition
- classification models
- transfer learning
- data augmentation
- inference-optimized deployment-ready architectures
This allows our models to perform not only in controlled test conditions, but also in real operational environments.
Why Inference and OCR Are Implemented in C++
Although Python is extremely powerful for training and experimentation, it is not always the ideal choice for real-time runtime environments.
In actual field deployments, systems must often process live video streams, handle multiple cameras, generate results with low latency, and operate continuously for long periods. In these scenarios, C++ provides a much stronger runtime foundation.
That is why in our architecture:
- OCR operations
- inference execution
- image processing pipelines
- real-time frame handling
- camera stream management
- performance-critical modules
are implemented on the C++ side.
Advantages of Performing Inference in C++
1. Higher speed
C++ is a compiled language with low-level access to memory and hardware resources. This allows more efficient execution for performance-critical workloads such as inference and OCR.
2. Lower latency
In real-time systems, total processing speed is important, but response latency is equally critical. The time between frame acquisition and result generation must be as low as possible. C++ can significantly reduce this latency.
3. Better memory control
Large images, video streams, and multi-camera systems place heavy pressure on memory usage. C++ gives developers much more control over memory allocation, reuse, and optimization.
4. Better suitability for real-time systems
Many computer vision systems operate continuously in the field. They must:
- process live camera streams
- run detection and OCR
- generate alerts
- store results
- deliver outputs with minimal delay
C++ is naturally better suited for such always-on, real-time environments.
5. More efficient use of hardware resources
CPU, GPU, and hardware acceleration pipelines can often be used more efficiently in a C++ runtime. This becomes especially important in optimized inference systems.
6. Easier low-level integration
Many industrial systems, camera SDKs, video pipelines, and embedded platforms are based on C or C++. A C++ inference engine can integrate more naturally with these environments.
Why C++ Is Better Suited for Real-Time Computer Vision
A computer vision system is not just about running a model once. In real deployments, the system must handle many operations at the same time:
- frame acquisition from camera streams
- frame buffer management
- preprocessing
- inference
- OCR
- post-processing
- tracking
- event generation
- database logging
- result delivery to the user interface
When all of these tasks are combined, the software architecture must be highly efficient to maintain real-time performance.
C++ stands out in this area because it provides:
- lower runtime overhead
- stronger native execution performance
- efficient multithreading capabilities
- low-level optimization opportunities
- better performance in high-FPS scenarios
- more deterministic runtime behavior
This makes C++ especially well suited for:
- multi-camera systems
- high-resolution video analytics
- OCR-based real-time recognition
- security applications with instant alerts
- industrial computer vision deployments
Python or C++: Which One Is Better?
In practice, this is not the right question. The better question is:
Which language is best suited for each layer of the system?
Because in reality:
- Python is ideal for training and AI research
- C++ is ideal for runtime and performance-critical operations
The most effective architecture is to use each technology where it performs best.
In our system design:
- models are trained in Python using PyTorch and TensorFlow
- trained models are prepared for deployment
- OCR, inference, and performance-critical runtime operations are executed in C++
This approach combines the flexibility of modern AI development with the speed and efficiency required in real-world deployments.
Why OCR and Inference Should Run in the Same Performance Layer
In OCR-based systems, inference is only one part of the runtime pipeline. A complete OCR workflow usually includes:
- image acquisition
- region detection
- cropping
- resizing
- normalization
- model inference
- character decoding
- result validation
- rule-based post-processing
In this kind of pipeline, every millisecond matters. If the system is used in traffic monitoring, security, access control, or industrial automation, the processing chain must be fast, predictable, and stable.
A C++ runtime layer for OCR provides clear advantages:
- faster end-to-end pipeline execution
- more controlled resource usage
- higher throughput
- lower response time
- stronger real-time behavior
Why Performance Matters So Much in Field Systems
A model may show excellent accuracy in a lab environment. But the real question is:
Can it run in real time, reliably, and continuously in the field?
This becomes critical in applications such as:
- license plate recognition systems
- city surveillance platforms
- parking entry and exit systems
- container code recognition
- wagon code recognition
- multi-camera analytics
- vehicle make / type / color recognition
- event detection and alert systems
In these projects, not only accuracy but also:
- speed
- stability
- scalability
- latency
- resource efficiency
are essential to the success of the system.
Our Software Architecture Approach
Our software architecture is built around a clear division of responsibilities.
Training Layer
- Python
- PyTorch
- TensorFlow
- modern deep learning techniques
- dataset preparation and model development workflows
Runtime / Inference Layer
- C++
- OCR operations
- high-performance inference
- real-time image processing
- camera and stream management
- low-latency field deployment logic
Application Layer
Depending on the project, additional technologies can be used for:
- user interface
- reporting
- database integration
- workflow management
This turns the solution into a complete operational product, not just an AI model.
Conclusion
Success in modern computer vision projects is not achieved only by training strong models. The real challenge is to run those models in the field with speed, stability, and real-time performance.
Python provides an outstanding ecosystem for model training through frameworks such as PyTorch and TensorFlow. C++, on the other hand, provides a faster, more efficient, and more deployment-oriented environment for inference, OCR, and other performance-critical operations.
That is why using Python for training and C++ for runtime is a powerful and balanced architecture for modern AI systems.
Especially in real-time computer vision applications, the advantages of C++ in speed, latency, hardware efficiency, and runtime control make it a strong choice for production-grade deployment.